- Data: Attach scores to executions and traces and view them in the Langfuse UI
- Filter: Group executions or traces by scores to e.g. filter for traces with a low-quality score
- Fine Tuning: Filter and export by scores as .csv or .JSONL for fine-tuning
- Analytics: Detailed score reporting and dashboards with drill downs into use cases and user segments
How to integrate?
Setup
Enter your Langfuse API keys and OpenAI API key You need to sign up to Langfuse and fetch your Langfuse API keys in your project’s settings. You also need an OpenAI API key- Context Relevance: Evaluates how relevant the retrieved context is to the question specified.
- Factual Accuracy: Evaluates whether the response generated is factually correct and grounded by the provided context.
- Response Completeness: Evaluates whether the response has answered all the aspects of the question specified
Using Langfuse
You can use Langfuse in 2 ways:- Score each Trace: This means you will run the evaluations for each trace item. This gives you much better idea since of how each call to your UpTrain pipelines is performing but can be expensive
- Score as Batch: In this method we will take a random sample of traces on a periodic basis and score them. This brings down cost and gives you a rough estimate the performance of your app but can miss out on important samples.
Method 1: Score with Trace
Now lets initialize a Langfuse client SDK to instrument you appMethod 2: Scoring as batch
Let’s create trace with our original dataset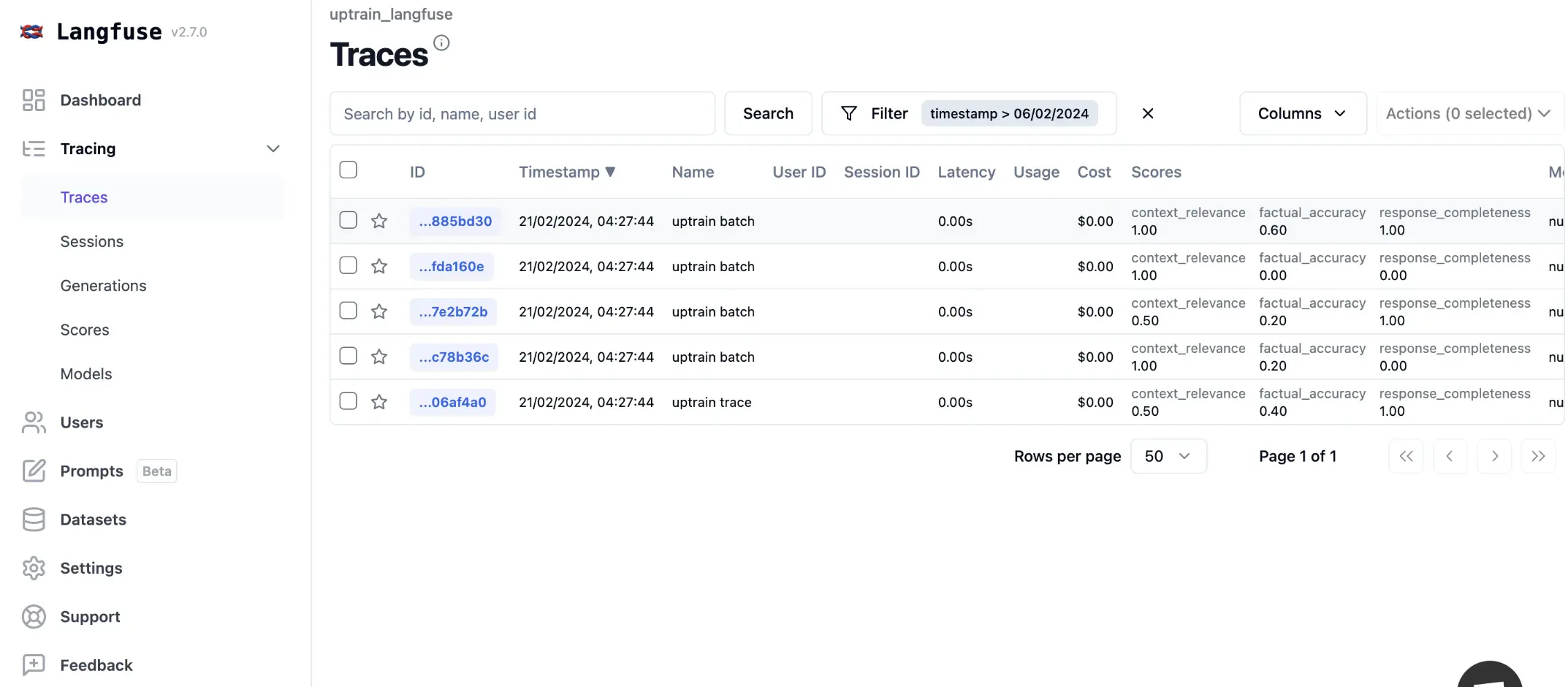
Tutorial
Open this tutorial in GitHub
Have Questions?
Join our community for any questions or requests