How to integrate?
Prerequisites
2
Define OpenAI client
3
Let's define our dataset
4
Define your prompt
5
Define funtion to generate responses
6
Define UpTrain Function to run Evaluations
- Response Conciseness: Evaluates how concise the generated response is or if it has any additional irrelevant information for the question asked.
- Factual Accuracy: Evaluates whether the response generated is factually correct and grounded by the provided context.
- Context Utilization: Evaluates how complete the generated response is for the question specified given the information provided in the context. Also known as Reponse Completeness wrt context
- Response Relevance: Evaluates how relevant the generated response was to the question specified.
7
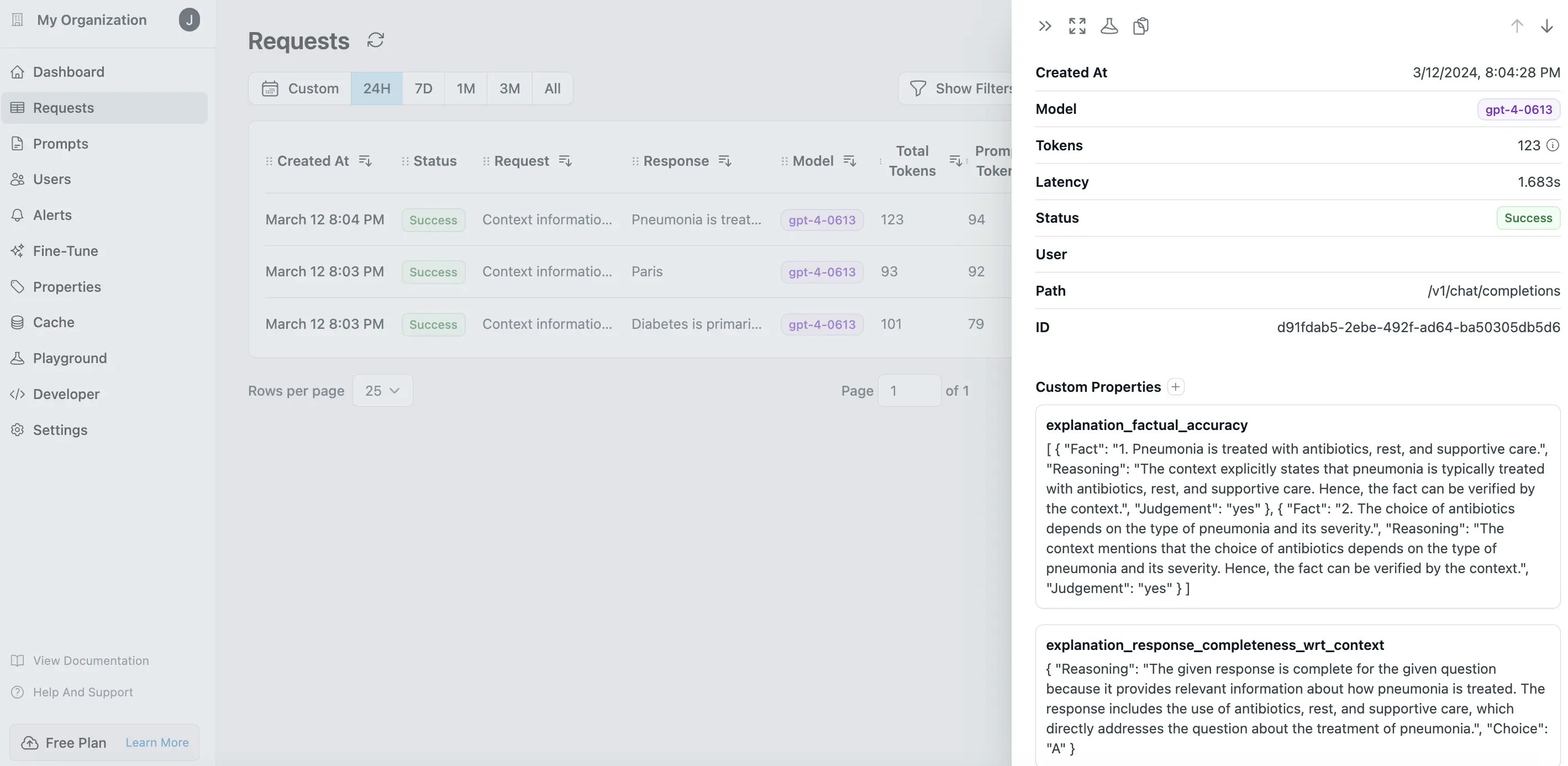
Run the evaluations and log the data to Helicone t
Visualize Results in Helicone Dashboards
You can log into Helicone Dashoards to observe your LLM applications over cost, tokens, latency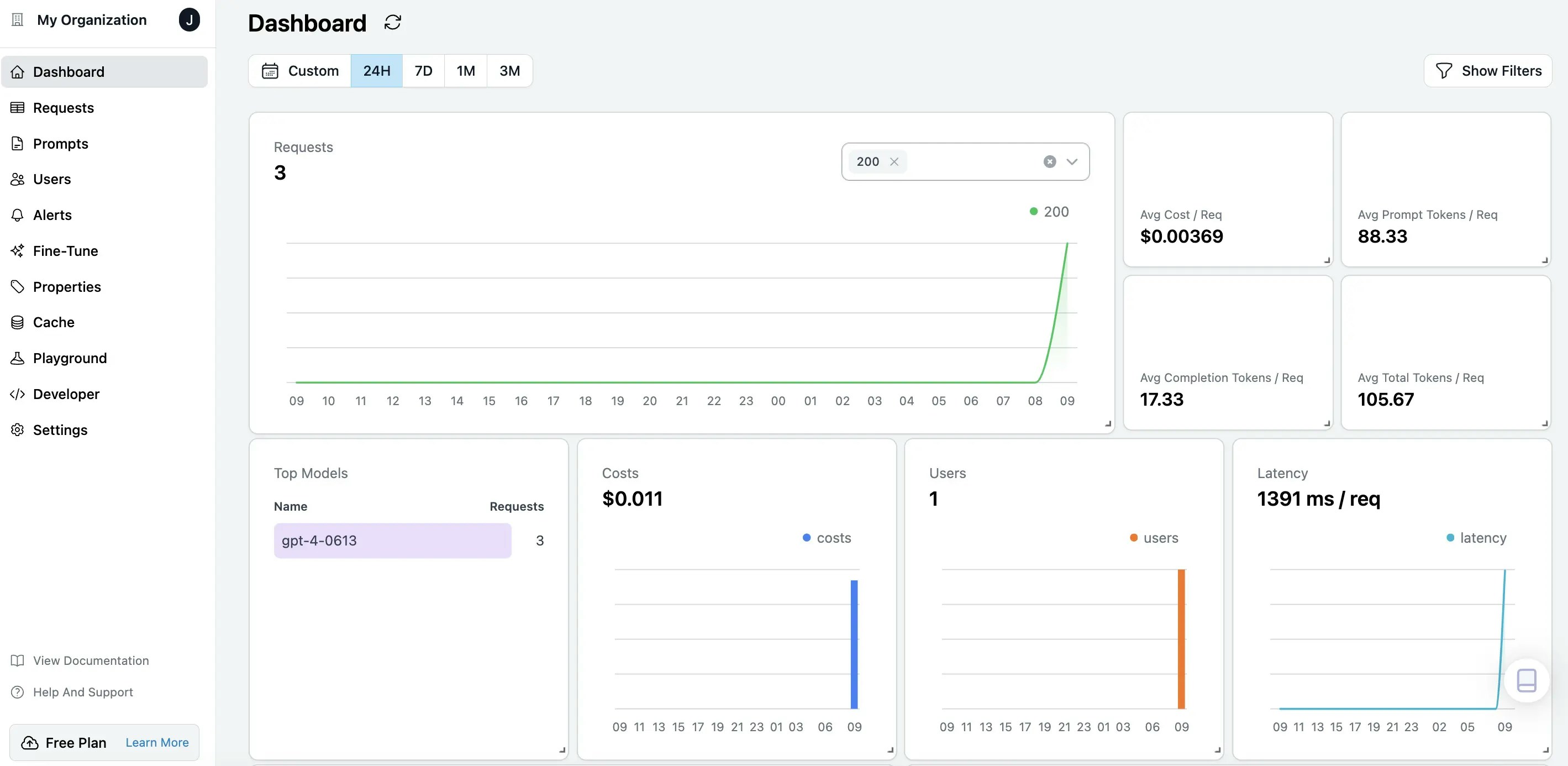
Tutorial
Open this tutorial in GitHub
Have Questions?
Join our community for any questions or requests