- Check for the total number of distinct words
- Check for the average number of unique words
- Check for the presence of “numbers”
1
Install UpTrain
Install UpTrain by running the following command:
2
Define the custom evaluation
We will use UpTrain to check for these custom evaluations over the following cases:Example 1: Check for the average number of unique wordsExample 2: Check for average length of words
- Check for the average number of unique words
- Check for average length of words
Note: Please ensure to add the prefix “score_” to the value in col_out_score if you wish to log these results on uptrain’s locally hosted dashboard
3
Run the evaluations
Let’s define a datasetAll done! Now let’s run these evaluations
Note: By default UpTrain runs locally on your system. You can also ensure this by passing Settings(evaluate_locally=True) to EvalLLM
4
Visualize these results
Now that you have generated these evaluations, you can also visualize the results on UpTrain’s Dashboard.This Dashboard is a part of UpTrain’s open-source offering and runs locally on your device.Check out this documentation to get started with UpTrain Dashboard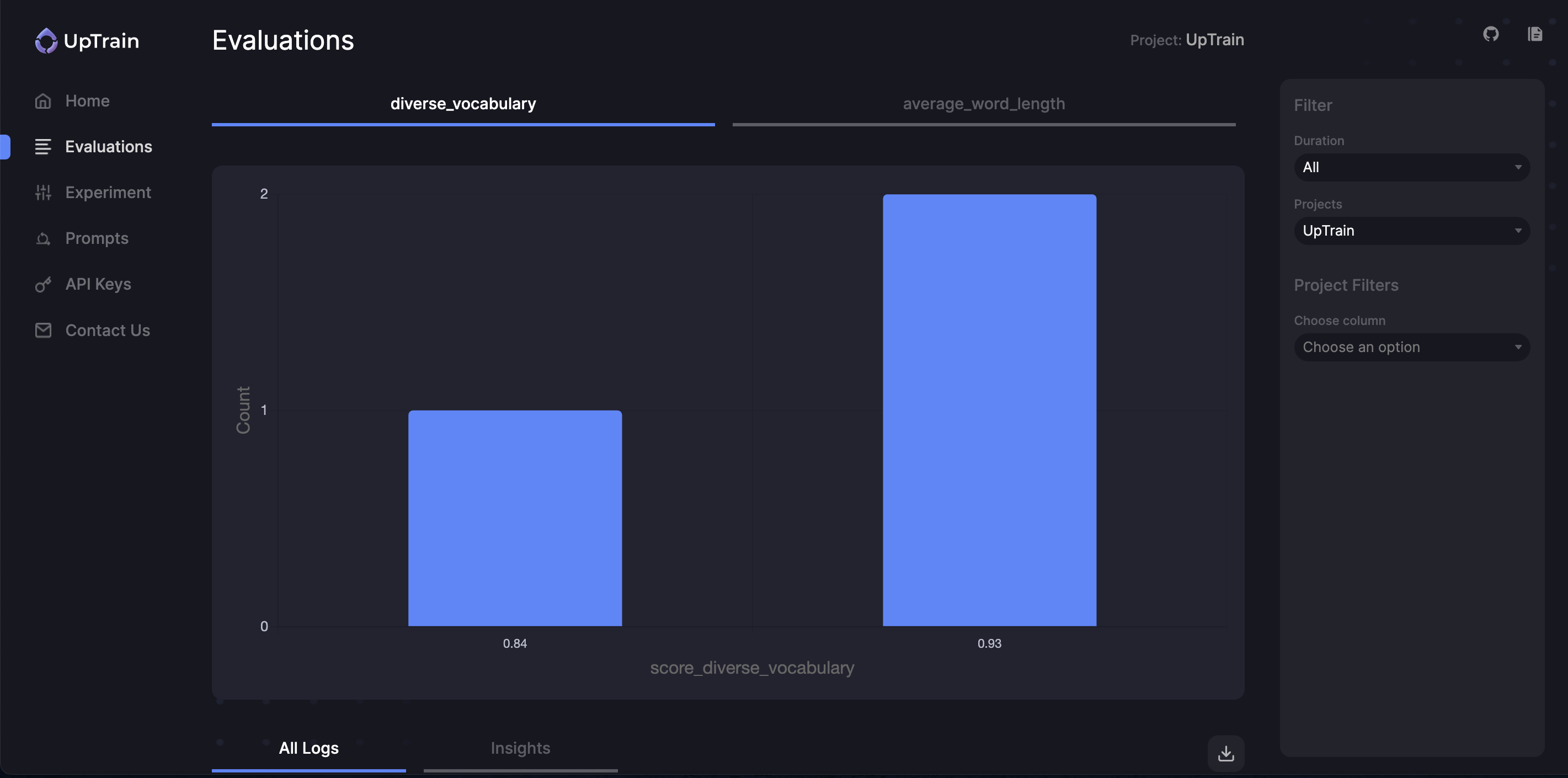
Bonus
We have already defined some prebuilt evaluations that you can use without the hassle of writing the code for themNote: If you face any difficulties, need some help with using UpTrain or want to brainstorm on custom evaluations for your use-case, speak to the maintainers of UpTrain here.
Tutorial
Open this tutorial in GitHub
Have Questions?
Join our community for any questions or requests